Sentiment Analysis
Goal
The goal of this component was to calculate the sentiment score of a tweet ranging from 0 to 1. A sentiment score below 0.5 and closer to 0 corresponds to negative sentiment, whereas a sentiment score greater than 0.5 and closer to 1 corresponds to positive sentiment.
Training data
The dataset that we used to train our classifier is the Sentiment140 dataset which consists of 1.6 million labeled tweets of multifarious content. In the early stages of development, this dataset was augmented with cases from the Twitter US Airline Sentiment dataset. However, we quickly realized that the type and tone of language used in airline short reviews differs significantly from this used in political comments. For example, this dataset contained many cases classified as positive sentiment tweets in which a user would write “thank you” to show appreciation for the services of a particular airline. However, we observed that in the vast majority of political tweets related to the democratic primaries, the phrases “thank you” or “no, thanks” were used in a sarcastic manner to convey negative sentiment about a candidate. Hence, we decided to remove this dataset from our training data. Instead, we augmented Sentiment140 with the GOP Debate Twitter Sentiment dataset which consists of 13900 labelled tweets related to the GOP Debate held in August 2016. This dataset was used since it contains tweets with similar content and language to the tweets related to the democratic primaries.
The final model was trained on 966436 instances, validated on 322147 instances and tested on a held out test set of 322147 instances. All of the sets contained a mix of randomly shuffled Sentiment140 and GOP Debate tweets.
Preprocessing
The tweets were first preprocessed to remove hashtags, mentions and web links, which do not carry any syntactic information or sentiment signal. We also defined a list of stopwords which are the most frequently used words not carrying any sentiment information (e.g. “the”, “a”, “this”, “you” etc.) and removed such words from each tweet. Please note that words like “no” or “not” may be considered stopwords in the NLP literature, however, in the scope of sentiment analysis, such words drive the polarity of a sentence. For example, the word “nice” should result in positive sentiment. However, the phrase “not nice” should result in negative sentiment. Hence, we did not remove such words from the tweets.
Furthermore, Sentiment140 comes preprocessed, since emoticons have already been removed by tweets. In the same fashion, we removed emoticons from the GOP Debate Twitter Sentiment dataset. As it is also mentioned in literature (Go et al. 2009), stripping out the emoticons lets the model learn from the other words used in the sentence. Instead, if emoticons are not stripped off, classifiers tend to put a high weight on the emoticons which results in lower performance when trying to classify tweets without emoticons or with multiple ones.
Model
From tweets to sequences
As it was also noted in the literature review section, deep neural networks achieve state-of-the-art performance on natural language processing tasks, especially in sentiment analysis. For this reason, we decided to experiment with various deep learning architectures for this task using Keras.
Like most of the classifiers, raw text cannot be used as the input to neural networks. Instead, the pre-processed tweets were tokenized and each word was mapped to a number in an index. Then each tweet was represented by a fixed-size sequence of numbers (any tweets with less words than the maximum length, were padded with zeros) which was the input to the neural network.
Word Embedding
The first layer of each neural network that we tried was an embedding layer. With word embedding, we refer to the process of associating each word with a dense, low-dimensional vector. The goal of word embeddings is to create a mapping between semantic information and geometric interpretation. For example, synonyms could be mapped to vectors which are parallel or have comparable norm in specific embedding spaces. Word embeddings can be learned from data jointly with the main task (for example prediction). In this way, a word embedding which is suitable for the given data and task can be learned. Alternatively, one can use a pre-trained word embedding which fits the given task. There are several publicly available word embeddings which have been trained on different types of language, like Word2Vec or GloVe.
Baseline model
Firstly, we fitted a baseline model which consisted of an embedding layer which was then fed to a Dense hidden layer of 32 neurons. The embedding layer which mapped words to 100-dimensional vectors was also trained with the rest of the network. This network achieved a validation accuracy of about 79%.
Recurrent Neural Network
Text data is sequential. In other words, the meaning of a sentence is updated with each word added to it. A human is reading each sentence by processing it word by word, while keeping an internal state of what preceded each word. Unlike feedforward neural networks, recurrent neural networks use the same logic by iterating over the elements of a text sequence while keeping a state in memory which contains information related to the previous elements of the sequence. For this reason, recurrent neural networks are a natural choice when it comes to sequential data and particularly text.
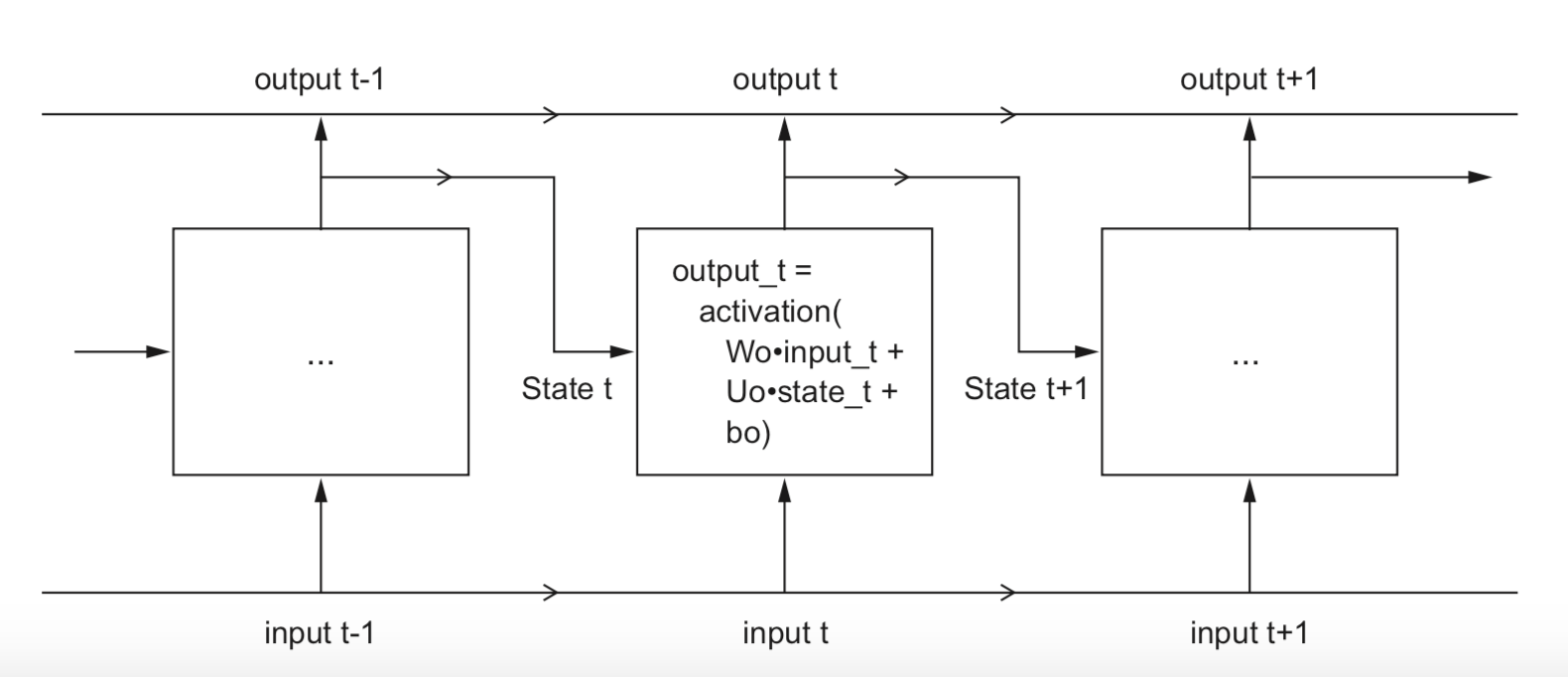 Figure: A toy recurrent neural network (source: Deep Learning with Python by Francois Chollet).
Figure: A toy recurrent neural network (source: Deep Learning with Python by Francois Chollet).
We experimented with LSTM (Long-Short-Term Memory) networks in Keras which are the most popular types of recurrent neural networks. We also experimented with a bidirectional LSTM network but this did not achieve higher performance than the unidirectional LSTM network.
Finally, we also experimented with using a pre-trained embedding layer instead of training it together with the rest of the layers added on top of it.
The model that we chose in the end is a recurrent neural network. Specifically, the first layer is an embedding layer which maps each word to a vector in a 100-dimensional space. The weights of this layer were not trained since we used a pre-trained Twitter GloVE word embedding fitted on 2 billion tweets. The embedding layer feeds to a sequence of two LSTM layers of 64 and 32 neurons respectively, which then feed to a densely connected hidden layer of 32 neurons which uses the ReLU activation function. Finally, there is an output layer of one neuron which uses the sigmoid activation function to constrain the score between 0 and 1.
The code developed to fit the models can be found here.
Performance
Unfortunately, it was not possible to test the performance of the model on a large number of tweets related to the Democratic primaries, since relevant labelled Twitter datasets are not publicly available.
Instead, we held out 20% of the training dataset (more than 300000 tweets) to check how the model generalizes to unseen data. Similar to the training set, the test set consists of cases from both the Sentiment140 dataset and the GOP debate Twitter Sentiment dataset. Hence, the model was tested on a mix of political and non-political tweets. The model achieved accuracy of 82% on test set which is at par with the state-of-the-art techniques mentioned in the literature section too. The train and test set accuracy analysis of the selected model is summarized here.